Creación de documentos finales con ~!gurí_
Esta es una versión preliminar y en proceso de construcción. Muchos aspectos pueden cambiar drásticamente (incluso en sólo un par de días). Tenga presente este aspecto y revise siempre la que esté trabajando con última versión antes de iniciar esta etapa del trabajo editorial.
La creación de documentos finales y el rol del coordinador de producción en ~!guri_
~!guri_ le permite a los equipos editoriales de revistas científicas de acceso diamante automatizar y facilitar la etapa de producción, generando múltiples formatos de salida a partir de un manuscrito en formato .docx. Esta automatización está basada en un flujo de trabajo que establece un conjunto de pautas que deben seguirse para que este proceso se realice correctamente. Estas pautas incluyen una organización específica de las carpetas de trabajo, la carga de metadatos de forma estandarizada, así como el plantillado y marcación de los documentos manuscritos en formato .docx.
De modo esquemática podemos, dividir este flujo de trabajo diferenciando los roles del Coodrdinador de producción (o Editor de producción) y del Corrector de pruebas, los cuales no necesariamente tienen que ser desarrollados por personas diferentes. En este documento nos centraremos en las tareas específicas del Coodrdinador de producción (ver la sección Corrección de pruebas para las tareas del Corrector de pruebas). Las tareas específicas del Coodrdinador de producción o Editor de producción serán:
- Coordinar el proceso general de la etapa de corrección de pruebas, garantizando la correcta organización de los archivos finales (ver sección Organización de carpetas de trabajo).
- Cargar los metadatos de los autores, el artículo y el volumen/número al que corresponde el dicho artículo (ver sección Metadatos).
- Centralizar las modificaciones realizadas por el Corrector de pruebas, asegurando que los manuscritos estén listos para la generación de los documentos finales (ver sección Corrección de pruebas). En particular, la generación de tablas es un asecto que muchas veces es realizado directamente (o requiere la intervención) del Coodrdinador de producción (ver sección Tablas).
- Generar los documentos finales con el paquete
{guri}.
~!guri_.
| Coordinador de producción | Corrector de pruebas |
|---|---|
| Coordinar el proceso general de la etapa de corrección de pruebas, garantizando la correcta organización de los archivos finales | Hacer una marcación y diferenciación de los diferentes bloques de contenidos, como títulos, texto, citas, etc. |
| Cargar los metadatos de los autores, el artículo y el volumen/número al que corresponde el dicho artículo | Hacer una lectura general del artículo, corrigiendo problemas de redacción, gramaticales u ortografía |
| Centralizar las modificaciones realizadas por el Corrector de pruebas, asegurando que los manuscritos estén listos para la generación de los documentos finales | Verificar el formato y la correcta inclusión de las Tablas y Figuras para que puedan ser incorporadas correctamente en la etapa siguiente |
Generar los documentos finales con el paquete {guri} |
Identificar y marcar las referencias bibliográficas mediante el uso de un gestor de referencias |
| Plantillar, corregir o generar los anexos cuando sea necesario |
A comtinuación se describen los pasos necesarios para la organización de carpetas de trabajo, la generación de metadatos y la generación de los documentos finales a partir de un manuscrito. Las tareas correspondientes a la etapa de corrección de pruebas se describen en la sección dedicada a la Corrección de pruebas, mientras que el tratamiento de las tablas se aborda en la sección sobre la construcción de Tablas.
Organización de carpetas de trabajo
Para comenzar con la edición y generación de documentos es necesario que previamente haya instalado el paquete {guri} y las dependencias necesarias, configurando su entorno de trabajo. Además, para poder utilizar ~!guri_ es necesario que haya creado previamente una revista (ver la sección Configuración).
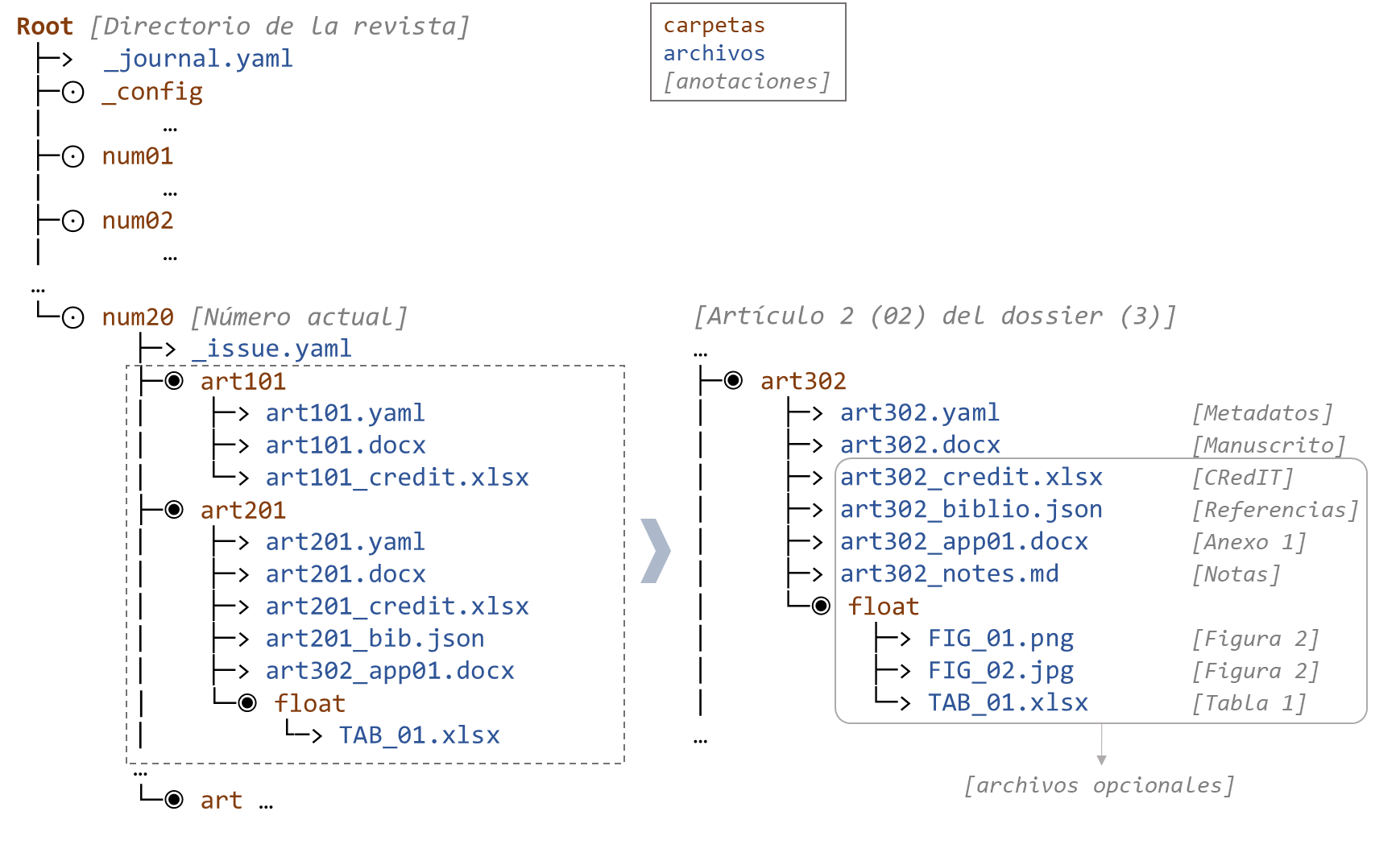
Dentro de la carpeta de la revista, deberá generar una carpeta para cada número de la revista. La única regla respecto a este punto es que las carpetas de los números de la revista estén alojadas directamente en la carpeta de la revista (no anidando subcarpetas). Más allá de esto, es recomendable que las carpetas de los números de la revista sigan una estructura de nombres que permita ordenar los números de forma natural. Para ello, es una práctica común utilizar prefijos que indiquen (como ‘vol’ o ‘issue’) seguido de un número. Por ejemplo, si su revista utiliza volúmenes y números, podría utilizar como nombre para la carpeta vol[~]issue[~] (por ejemplo, vol02issue03 para el volumen 2, número 3).
Dentro de cada carpeta correspondiente a un número de la revista, deberá colocar un archivo ’_issue.yaml’ con los metadatos del número. Puede encontrar un modelo de este archivo en la carpeta ’_default-files’, dentro del directorio de la revista. Además, dentro de la carpeta del número deberá generar una carpeta para cada artículo del número. Las carpetas de los artículos deben comenzar con el prefijo ‘art’ seguido de tres números que identifican el artículo (el ‘id del artículo’)
Por ejemplo, si su revista utiliza secciones y numeración de artículos, podría utilizar como nombre para la carpeta art[~] (por ejemplo, art302 para el artículo 2 de la sección 3).
Para cada número se creará una carpeta independiente que contendrá un archivo _issue.yaml con la información básica del número. Dentro de esta carpeta se deberá generar una carpeta independiente para cada artículo. Las carpetas de cada artículo deben utilizar una estructura de prefijos común, de manera que empiecen por la sílaba ‘art’, seguida de un identificador de un dígito para la sección y dos dígitos que identifiquen a los artículos en un orden secuencial que se espera sean presentados (ver recuadro con ejemplo). En caso de que la revista no tenga sección podrá usar una numeración continuada con tres dígitos.
Si su rebista tuviera las siguientes secciones:
- Editorial;
- Artículos del dossier;
- Artículos de sección abierta;
De esta manera, suponiendo que nuestro artículo pertenezca al Dossier (3) y sea el segundo en orden dentro de esta sección (02), el nombre de la carpeta sería art302.
Dentro de cada carpeta de artículo es obligatorio que haya los siguientes archivos:
art[~].yaml(ejemplo:art302.yaml): Contiene los metadatos del artículo (autores, el título, el resumen, etc).art[~].docx(ejemplo:art302.docx): Contiene el manuscrito corregido, con las referencias identificadas mediante gestor de referencia (si las hubiere).
Además de estos archivos es posible encontrar uno o más de los siguientes archivos opcionales:
art[~]_credit.xlsx(ejemplo:art302_credit.yaml): Contiene una tabla con la información sobre la taxonomía CRediT, referida a las contribuciones de los autores individuales.art[~]_app[~].docx(ejemplo:art302_app01.docx): Contiene los anexos vinculados al manuscrito. Es posible que exista uno o más archivos de este tipo (dependiendo de la cantidad de anexos). Debería estar presente sólo si existen anexos en el manuscrito.art[~]_notes.md(ejemplo:art302_notes.md): En este archivo se podrá incluir cualquier tipo de observación o comentario que se considere pertinente comunicar. El archivo está en formato Markdown, por lo que se recomienda el uso de los marcadores asociados a este lenguaje de marcación (ver Tutorial de Markdown y Editor online). Recuerde que este archivo es simplemente un archivo de texto plano (por ejemplo un.txt) con una extención.md. Sólo puede haber un archivo de este tipo por artículo. El archivo sólo estará presente si hay comentarios durante el proceso de corrección de pruebas.
Además de estos archivos, dentro de cada carpeta de artículo podrá haber una carpeta ./float con varios archivos en donde estarán las Tablas y Figuras (ver sección Elementos flotantes para mayor desarrollo).
Para ilustrar la organización de archivos prevista, si el artículo que se está corrigiendo corresponde al Número 20 de la revista, entonces la carpeta del segundo artículo de la sección “3” (./art302) deberá tener la estructura de archivos que se presenta en la Figura 1.
Metadatos
Información del volumen/número: el archivo _issue.yaml
[TODO] El archivo
issue.yaml.
Para la identifiación de los metadatos del número y el artículo se utilizará como modelo el documento _issue.yaml y _article.yaml, respectivamente (ver carpeta ./default-files).
La información de los artículos: el archivo art[~].yaml
[TODO] Desarrollar la descripción de los elementos a completar en
art[~].yaml.
Taxonomía CRediT
Si la revista utiliza la taxonomía CRediT para identificar la contribución de los autores, entonces deberá proporcioanrse para cada artículo un archivo art[~]_credit.xlsx. Este archivo, deberá tener una primera columna (‘CREDIT’) con los catorces roles identificados por esta taxonomía[^1] y una columna para cada autor (vea el modelo disponible en la carpeta ./default-files). Para indicar la contribución de cada autor deberá agregar una ‘x’ (equis minúscula). Es importante que esta tabla no contenga columnas que no referencien a los autores (no deje las columnas de la plantilla en blanco). Por el momento, no es posible utilizar una escala de contribución para cada uno de los roles. Tenga en cuenta que autor puede haber contribuido en más de uno de los roles. El programa no corrobora si las contribuciones atribuidas a cada autor se consideran sustanciales y suficientes para generar atribución de autoría.
Generación de documentos finales
Una vez finalizada la organización de las carpetas de trabajo (Organización de carpetas de trabajo), la carga de metadatos (Metadatos) y la etapa de corrección de pruebas (ver Corrección de pruebas), es posible generar los documentos finales de los artículos. Para ello, debe abrir R, cargar el paquete {guri} y ejecutar la función guri_outputs. Los parámetros de esta función son los siguientes:
art_id: Identificador del artículo o artículos que se desea generar. Puede ser un vector de caracteres con los identificadores de los artículos o la palabra"all"para generar los documentos finales de todos los artículos del número.issue: Número del volumen/número que se desea generar. Debe ser un caracter.journal: Nombre de la revista. Debe ser un caracter.doi_batch: Valor lógico que indica si se desea generar un archivo XML con los metadatos de todos los artículos del número para realizar el depósito DOI en Crossref. Por defecto esFALSE.
Además, existen dos parámetros que resultan útiles para detectar errores. Por un lado, el parámetro verbose que permite mostrar mensajes de progreso durante la ejecución de la función (por defecto TRUE). Por su parte, el parámetro clean_files indica si se desea reorganizar los archivos generados en carpetas (por defecto TRUE).
Como ejemplo tomemos la revista “NEW_JOURNAL”, la cual sigue el modelo de “repositorio de revistas”. Si usted desea generar los documentos finales de todos los artículos del número que está alojado en la carpeta issue14, deberá ejecutar el siguiente código:
library(guri)
guri_outputs(art_id = "all",
issue = "issue14",
journal = "NEW_JOURNAL")En caso de que quiera generar sólo algunos artículos (por ejemplo, los art101, art201 y art302), deberá ejecutar el siguiente código:
library(guri)
guri_outputs(art_id = c("art101", "art201", "art302"),
issue = "issue14",
journal = "NEW_JOURNAL")Como resultado, dentro de cada una de las carpetas de los artículos se generará una carpeta ./output con los documentos finales en los formatos PDF, HTML y XML. El nombre de estos archivos será art[~].pdf, art[~].html y art[~].xml (es decir, para el artículo art101, los archivos art101.pdf, art101.html y art101.xml). Además, en cada carpeta de artículo se generará una carpeta _temp con los archivos intermedios y auxiliares generados durante el proceso de conversión. En esta carpeta encontrará también un archivo xml con los metadatos del artículo, necesarios para realizar el depósito DOI en Crossref, sin embargo, es posible generar un archivo único con los metadatos de todos los artículos del número usando el parámetro doi_batch = TRUE (para más información, ver sección Depósito de DOI).